Overview
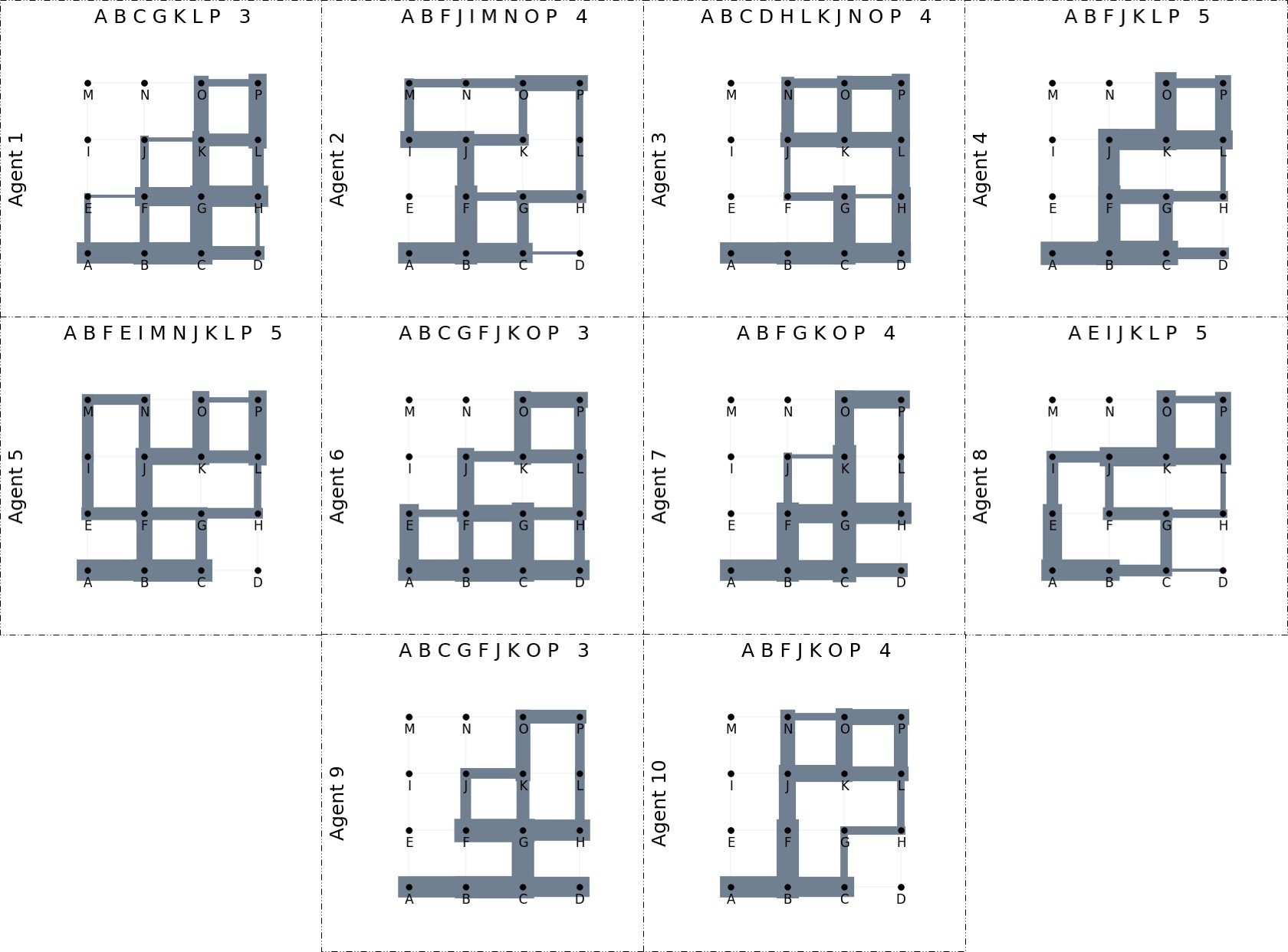
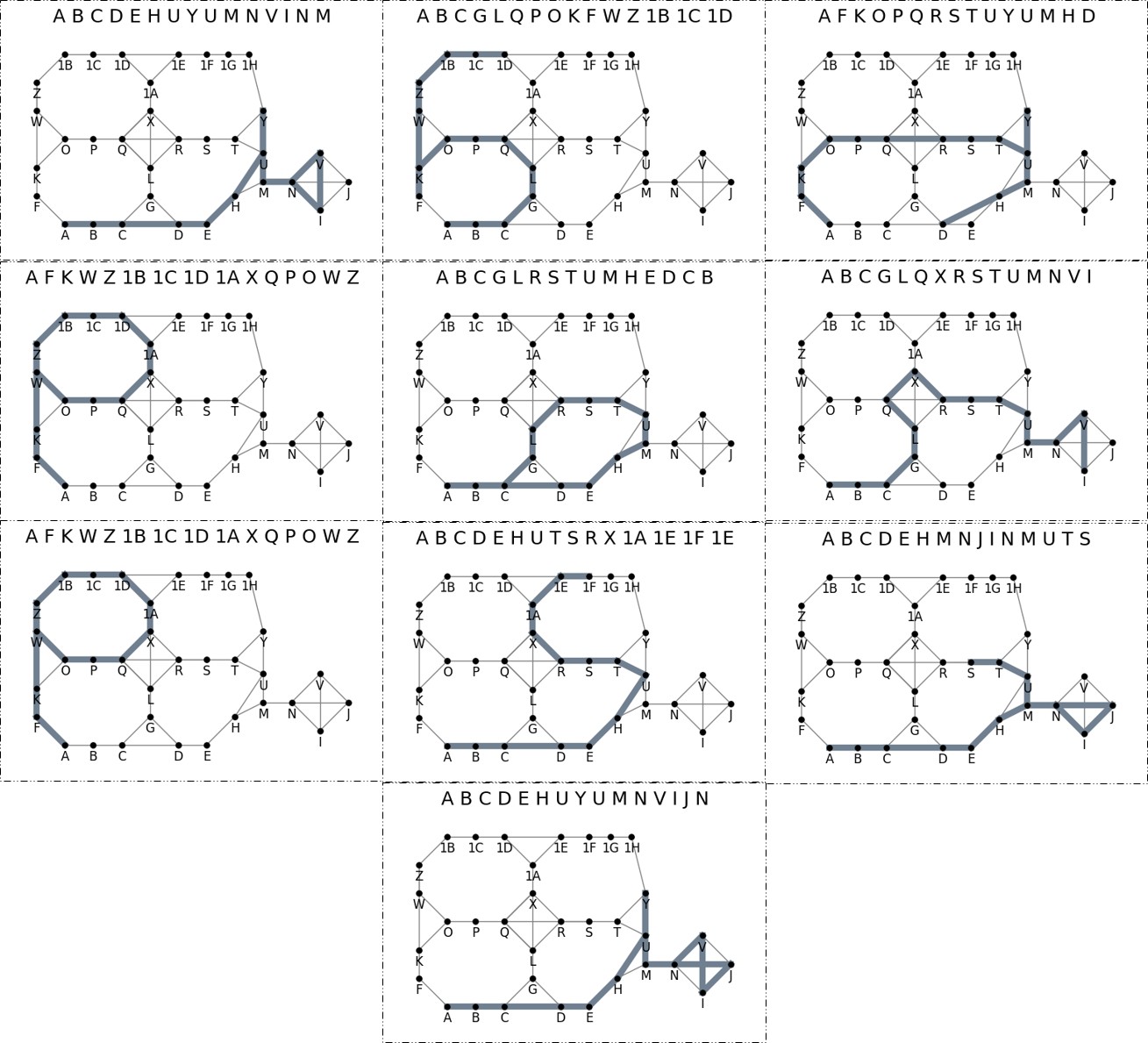
This study employs generative agents built on large language models to simulate human perception and movement in urban environments using street-view imagery; agents are endowed with virtual personalities, memory modules, and custom movement and visual inference components to plan journeys and rate locations on safety and liveliness, demonstrating a novel AI-driven framework for urban perception experiments.
Key Features
- Agents driven by large language models to generate human-like behaviors and decisions in urban contexts.
- Fetches Google Street View imagery via the GSV API for real-world environmental input into agent simulations.
- Custom movement module navigates a bidirectional graph of street nodes, while a visual inference module uses transformer-based segmentation models to extract scene details.
- Implements a memory database that stores observations with salience scoring (importance, recency) for retrieval during planning and reflection.
- Ten distinct agent profiles with 150-word backstories auto-generated via ChatGPT-3.5 to introduce variability in decision-making.
- Agents rate encountered scenes on dimensions like safety and liveliness, yielding quantitative urban perception metrics.
- Built on the LangChain library, providing modular functions for LLM orchestration, memory, movement, and visual processing.
Gallery

Technologies/Data Used
Large Language Models, Street View Imagery